SqlServer设备对接
操作步骤
登录物联网平台
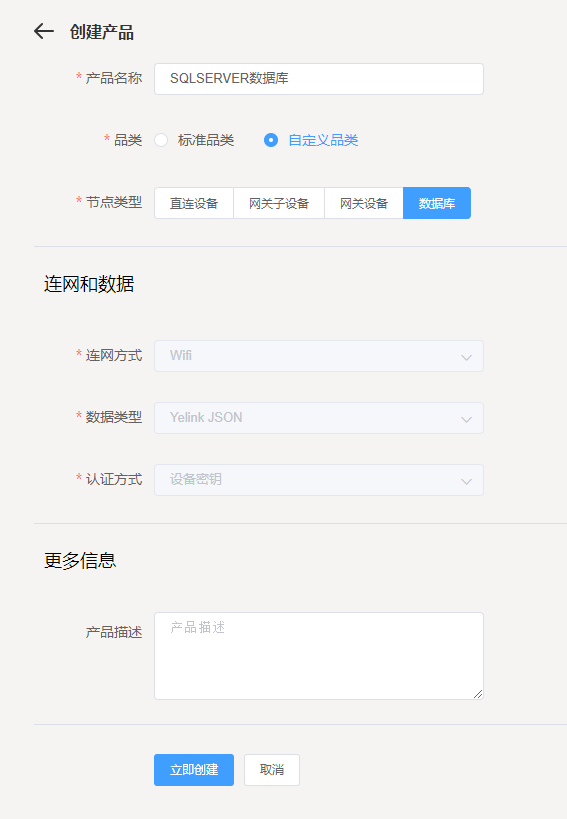
打开左侧菜单栏设备管理->产品->添加
品类选择自定义品类、节点类型选择数据库,其它默认,点击立即创建
打开左侧菜单栏设备管理->设备->添加
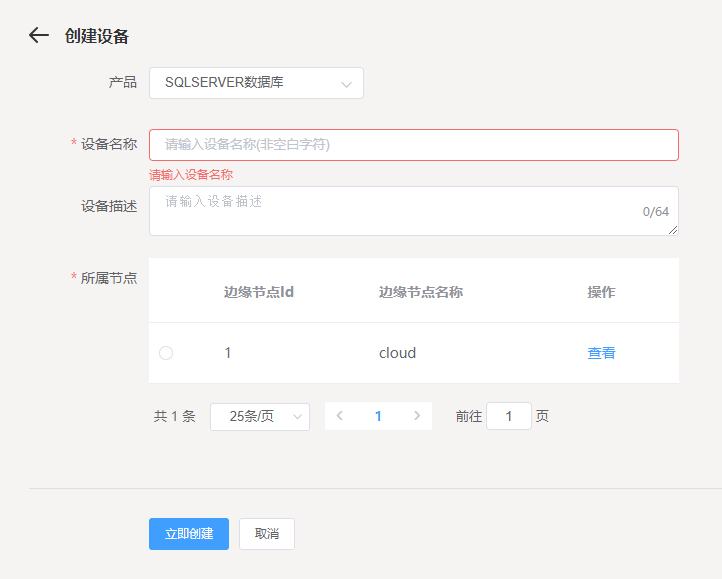
| 参数 | 描述 |
|---|---|
| 产品 | 选择产品。新创建的设备将继承该产品定义好的功能和特性。 |
| 设备名称 | 设置设备名称。设备名称在产品内具有唯一性。设备名称长度为4-32个字符,可包含英文字母、数字 |
| 设备描述 | 设备描述 |
| 所属节点 | 设备归属节点 |
- 创建采集任务
采集任务模板
{
"job": {
"setting": {
"speed": {
"byte": 1048576
}
},
"content": [{
"reader": {
// 插件名称
"name": "sqlserverreader",
"parameter": {
// 数据库连接用户名
"username": "sa",
// 数据库连接密码
"password": "yelink123",
"connection": [{
"querySql": [
"SELECT [strBatch] ,[strProductName],[g_Number_Sum] ,[g_Number_Good],[PT003_particle_ACT_R] ,[PT004_particle_ACT_R],[RecordTime] FROM [Filling].[dbo].[Tofflon_HisData_FM_History] where RecordTime > dateadd(minute,-19000,GETDATE());"
],
"jdbcUrl": [
"jdbc:sqlserver://192.168.103.61:1433;DatabaseName=master;socketTimeout=5000"
]
}]
}
},
"writer": {
// 插件名称
"name": "kafkawriter",
"parameter": {
"bootstrapServers": "192.168.101.160:9092",
"notTopicCreate":true,
"writeSize": 1000,
"dataType": "mark",
"fieldList": "strBatch,strProductName,g_Number_Sum,g_Number_Good,PT003_particle_ACT_R,PT004_particle_ACT_R,RecordTime"
}
}
}]
}
}
参数说明:
jdbcUrl
描述:描述的是到对端数据库的JDBC连接信息,使用JSON的数组描述,并支持一个库填写多个连接地址。之所以使用JSON数组描述连接信息,是因为阿里集团内部支持多个IP探测,如果配置了多个,SqlServerReader可以依次探测ip的可连接性,直到选择一个合法的IP。如果全部连接失败,SqlServerReader报错。 注意,jdbcUrl必须包含在connection配置单元中。对于阿里集团外部使用情况,JSON数组填写一个JDBC连接即可。
jdbcUrl按照SqlServer官方规范,并可以填写连接附件控制信息。具体请参看SqlServer官方文档.aspx)。
必选:是
默认值:无
username
- 描述:数据源的用户名
- 必选:是
- 默认值:无
password
- 描述:数据源指定用户名的密码
- 必选:是
- 默认值:无
querySql
- 描述:用户可以通过该配置型来自定义筛选SQL。例如需要进行多表join后同步数据,使用select a,b from table_a join table_b on table_a.id = table_b.id
当用户配置querySql时,SqlServerReader直接忽略table、column、where条件的配置。- 必选:否
- 默认值:无
bootstrapServers
- 描述: 配置写入kafka的地址
- 必选:是
- 默认值: 无
writeSize
- 描述: 一次性写入Kafka的数据条目
- 必选:是
- 默认值: 无
dataType
- 描述: 数据类型,会传入至Kafka数据,用户可以通过此字段区别数据类型,如:指标数据、告警数据
- 必选:是
- 默认值: 无
fieldList
- 描述: 写入Kafka的字段名称,对应从数据查询返回的表字段名,数量需与查询返回字段名一致。
- 必选:是
- 默认值: 无
kafka数据
数据示例:
{
"productKey": "5p3shctbhuj",
"devName": "devxxxxx",
"id": "815551986",
"version": "1.0",
"method": "thing.datax.property.post",
"dataType": "mark",
"params": {
"total": 2,
"list": [
{
"RecordTime": "2021-06-26 09:35:00",
"strProductName": "zk",
"g_Number_Sum": "96438",
"PT003_particle_ACT_R": "0.0",
"PT004_particle_ACT_R": "0.0",
"strBatch": "21040191",
"g_Number_Good": "80416"
},
{
"RecordTime": "2021-06-26 09:36:00",
"strProductName": "zk",
"g_Number_Sum": "96438",
"PT003_particle_ACT_R": "0.0",
"PT004_particle_ACT_R": "0.0",
"strBatch": "21040191",
"g_Number_Good": "80416"
}
]
}
}