数据库协议采集说明
操作步骤
登录物联网平台
打开左侧菜单栏设备管理->产品->添加
品类选择自定义品类、节点类型选择直连设备,协议类型选择数据库其它默认,点击立即创建
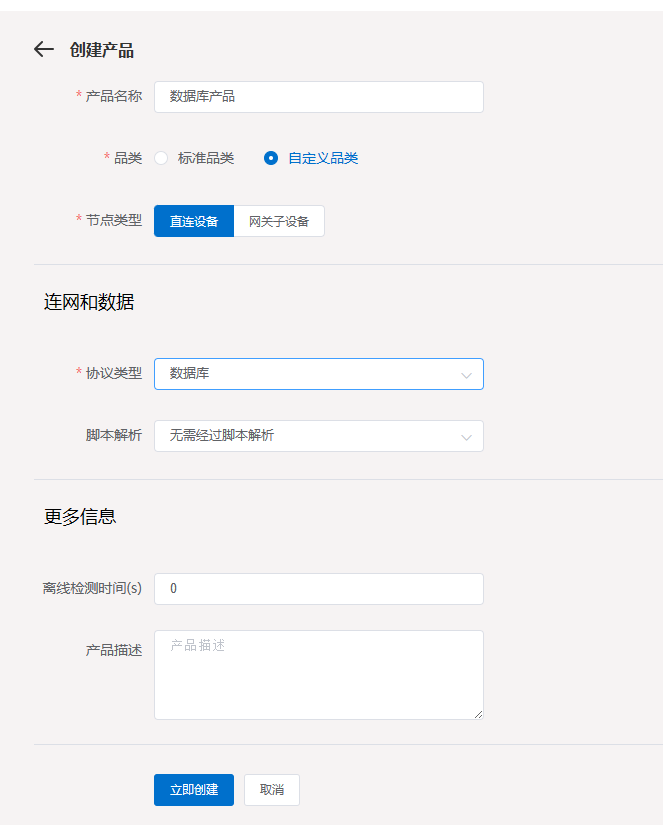
打开左侧菜单栏设备管理->设备->添加
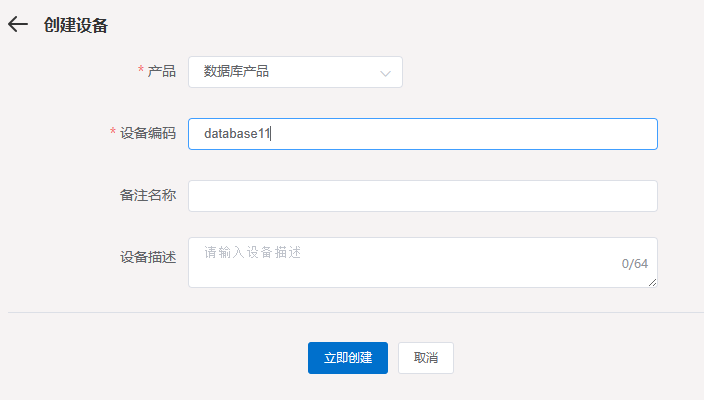
创建采集任务
方式一:通过上传文件的方式创建采集任务
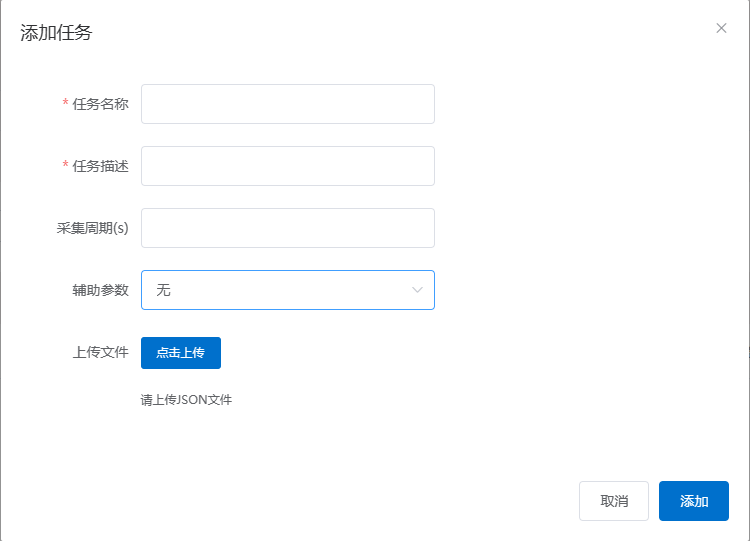
**辅助参数**: 增量数据采集的参数,详见增量配置说明
**上传文件**: 上传采集模板的文件,json格式的文件,详见模板文件说明
方式二: 通过web构建任务,创建采集任务
与方式一的区别是,不需要上传json模板文件,而是通过web指引构建采集模板
详见web构建任务
增量配置说明
根据日期进行增量数据抽取
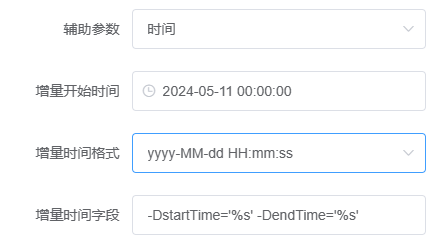
辅助参数选择时间
增量开始时间选择,即sql中查询时间的开始时间,用户使用此选项方便第一次的全量同步。第一次同步完成后,该时间被更新为上一次的任务触发时间,任务失败不更新。
- 增量时间字段,-DstartTime='%s' -DendTime='%s' 默认不要修改
1.-D是DataX参数的标识符,必配
2.-D后面的startTime和endTime是DataX json中where条件的时间字段标识符,必须和json中的变量名称保持一致
3.='%s'是项目用来去替换时间的占位符,比配并且格式要完全一致
4.注意-DstartTime='%s' -DendTime='%s'中间有一个空格,空格必须保留并且是一个空格
- 增量时间格式,可以选择自己数据库中时间的格式,也可以通过json中配置sql时间转换函数来处理
模板样例
{
"job": {
"setting": {
"speed": {
"byte": 1048576
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "xxx",
"password": "******",
"connection": [
{
"querySql": [
"select * from test where time >= ${startTime} and time < ${endTime} "
],
"jdbcUrl": [
"jdbc:mysql://xxxx:3306/test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&serverTimezone=GMT%2B8"
]
}
]
}
},
"writer": {
"parameter": {
"notTopicCreate": true,
"bootstrapServers": "192.168.101.xx:9092",
"dataType": "index",
"topic": "middle_priority_post",
"writeSize": 100,
"devName": "metering_system",
"productKey": "CP_sw2vwew8jco",
"fieldList": "id,data,time"
},
"name": "kafkawriter"
}
}]
}
}
querySql解析
select * from test where time >= ${startTime} and time < ${endTime}
上述where条件后的${startTime} 与${endTime}就是我们在增量时间字段配置的-DstartTime='%s' -DendTime='%s',${}是DataX动态参数的固定格式,sql里的字段需要与增量时间字段配置的字段一致。
根据自增Id进行增量数据抽取

- 辅助参数选择自增主键
- 增量主键开始ID选择,即sql中查询ID的开始ID,用户使用此选项方便第一次的全量同步。第一次同步完成后,该ID被更新为上一次的任务触发时最大的ID,任务失败不更新。
- 增量时间字段,-DstartId='%s' 先来解析下这段字符串
1.-D是DataX参数的标识符,必配
2.-D后面的startId是DataX json中where条件的id字段标识符,必须和json中的变量名称保持一致
3.='%s'是项目用来去替换时间的占位符,比配并且格式要完全一致
模板样例
{
"job": {
"content": [
{
"reader": {
"parameter": {
"password": "*****",
"connection": [
{
"querySql": [
"select e.ID,e.InspectTime, e.Result, e.PasteNum, e.Symbol, e.Reserved1byShort, e.Reserved2byShort, e.Reserved3byShort,e.Reserved2byChar, p.AreaId, p.Barcode from solder_pcb_v01_01 e LEFT JOIN barcode_v01 p on e.ID = p.PcbId where e.ID > ${startId};"
],
"jdbcUrl": [
"jdbc:mysql://172.16.0.16:3306/spi?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&serverTimezone=GMT%2B8"
]
}
],
"username": "root"
},
"name": "mysqlreader"
},
"writer": {
"parameter": {
"notTopicCreate": true,
"bootstrapServers": "172.16.0.8:9092,172.16.0.9:9092",
"dataType": "index",
"topic": "middle_priority_post",
"writeSize": 1000,
"devName": "SMT__SPI",
"productKey": "CP_mlofoehiuvd",
"fieldList": "ID,InspectTime,Result,PasteNum,Symbol,Reserved1byShort,Reserved2byShort,Reserved3byShort,Reserved2byChar,AreaId,Barcode",
"primaryKey": "ID"
},
"name": "kafkawriter"
}
}
],
"setting": {
"speed": {
"byte": 1048576
}
}
}
}
注意点
querySql里
select **** where e.ID > ${startId};此处的关键点在${startId},${}是DataX动态参数的固定格式,startId就是我们页面配置中 -DstartId='%s' 中的startId,注意字段一定要一致。
writer下面的primaryKey 需要填写主键ID字段。
web构建
添加任务,不需要上传文件。
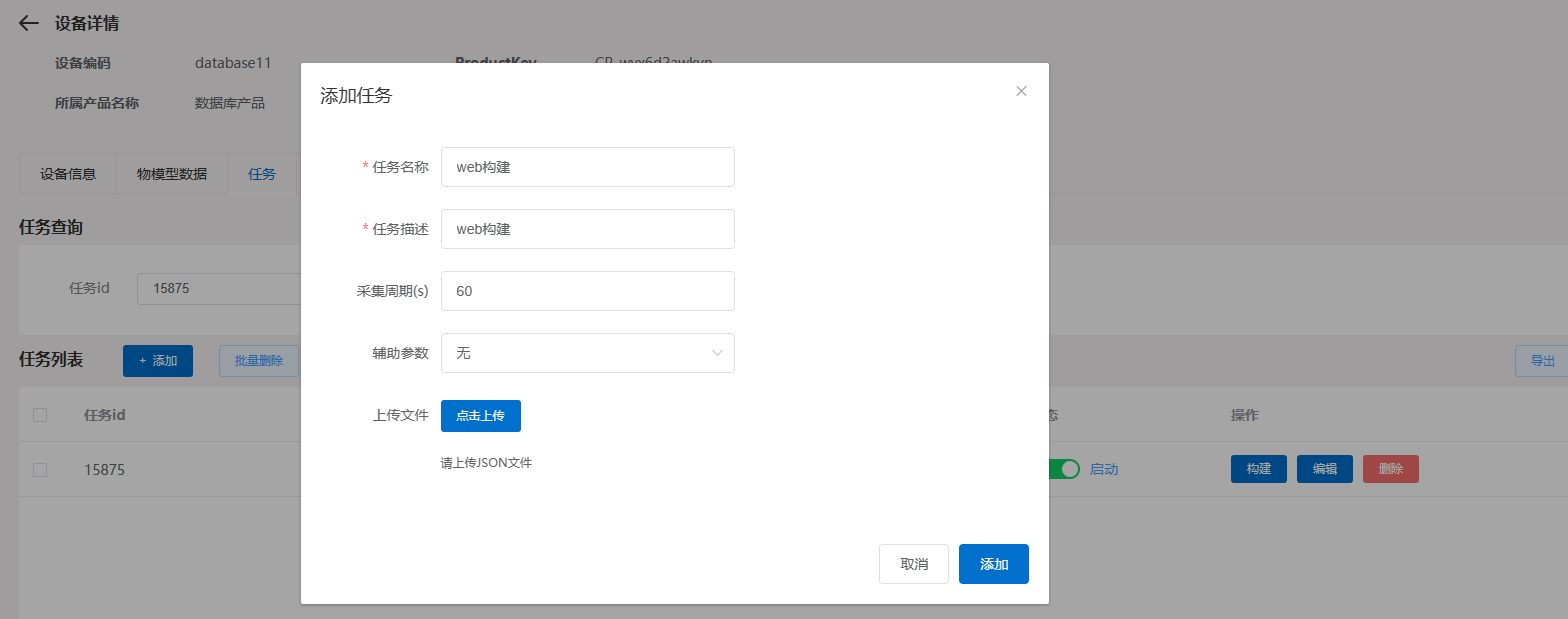
任务列表里选择上一步创建的任务,点击构建

构建reader
| 参数 | 描述 | | :--------- | :----------------------------------------------------------- | | 数据库源 | 选择要采集的数据库,如果不存在,请查看数据源管理篇章创建数据源 | | 数据库表名 | 采集的表,单表查询场景可以使用,涉及多表查询时,请使用SQL语句采集。 | | SQL语句 | sql查询,一般用于多表关联查询时使用 | | 切分字段 | Reader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。 | | 表所有字段 | 通过选择的数据库表名,或者SQL语句的字段解析出来的查询字段。 | | where条件 | 查询条件,不需要再加where |
构建writer
只讲解kafka Writer
| 参数 | 描述 | | :----------- | :------------------------------------------------- | | writer类型 | 数据库、kafka。主要使用kafka类型 | | 自增主键字段 | 只有创建任务的时候辅助参数选择自增主键,才需要选择 |
字段映射
端源字段: reader查询出来的所有字段,可以选择需要写入到writer的字段
目标字段: 表示写入到kafka的字段。
构建
步骤4点击构建按钮,生成json文本,点击下一步则完成所有构建步骤
数据源管理
在构建任务的步骤1,可以选择数据源管理
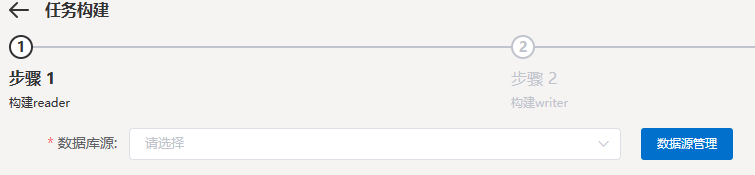
添加数据源
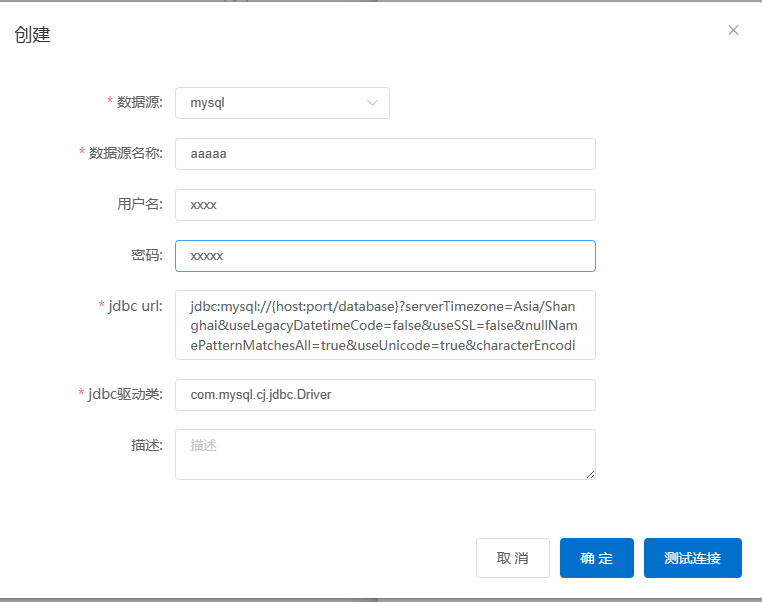
| 参数 | 描述 |
|---|---|
| 数据源 | 数据库类型,目前支持:mysql、oracle、sqlserver、access、postgresql、clickhouse |
| 数据源名称 | 数据源的名称 |
| 用户名 | 待添加的数据库的用户名 |
| 密码 | 待添加的数据库的密码 |
| jdbc url | JDBC连接地址,mysql模板jdbc:mysql://{host:port/database}?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8, 其中host:port/database 需要修改成实际的ip端口和库名 |
| jdbc驱动类 | 驱动类名,保持默认值即可。例如:com.mysql.cj.jdbc.Driver |
| 描述 | 数据源的描述 |